Support Vector Machines: Mathematical Insights
Support Vector Machines (SVMs) are powerful tools in machine learning, and their formulation can be derived from logistic regression cost functions. This article delves into the mathematical underpinnings of SVMs, starting with logistic regression and transitioning to the SVM framework.
Understanding Logistic Regression Cost Function
Logistic regression employs a hypothesis function defined as:
$$h_{\theta}(x) = \frac{1}{1 + e^{-\theta^T x}}$$
This function outputs the probability of $y = 1$ given $x$ and parameter $\theta$.
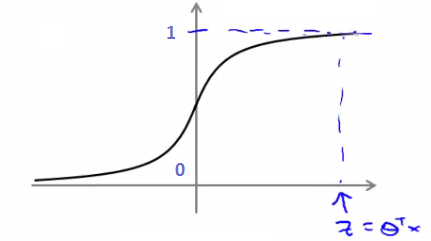
For a given example where $y = 1$, ideally, $h_{\theta}(x)$ should be close to 1. The cost function for logistic regression is:
$$\text{Cost}(h_{\theta}(x), y) = -y \log(h_{\theta}(x)) - (1 - y) \log(1 - h_{\theta}(x))$$

When integrated over all samples, this becomes:
$$J(\theta) = -\frac{1}{m} \sum_{i=1}^{m}[y^{(i)}\log(h_{\theta}(x^{(i)})) + (1 - y^{(i)})\log(1 - h_{\theta}(x^{(i)}))]$$
This cost function penalizes incorrect predictions, with the penalty increasing exponentially as the prediction diverges from the true value.
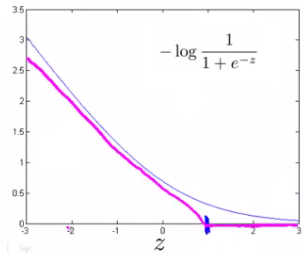
Transitioning to SVM Cost Functions
SVMs modify this logistic cost function to a piecewise linear form. The idea is to use two functions, $cost_1(\theta^T x)$ for $y=1$ and $cost_0(\theta^T x)$ for $y=0$. These functions are linear approximations of the logistic function's cost. The SVM cost function becomes:
$$J(\theta) = C \sum_{i=1}^{m}[y^{(i)} cost_1(\theta^T x^{(i)}) + (1 - y^{(i)}) cost_0(\theta^T x^{(i)})] + \frac{1}{2} \sum_{j=1}^{m} \theta_j^2$$
The parameter $C$ plays a crucial role in SVMs. It balances the trade-off between the smoothness of the decision boundary and classifying the training points correctly.
- A large $C$ applies a higher penalty to misclassified examples, leading to a decision boundary that might have lower bias but higher variance, potentially causing overfitting.
- A small $C$ makes the decision boundary smoother, possibly with higher bias but lower variance, risking underfitting.
Large Margin Intuition in SVMs
Support Vector Machines (SVMs) are designed to find a decision boundary not just to separate the classes, but to do so with the largest possible margin. This large margin intuition is key to understanding SVMs.
The Concept of Margin in SVMs
When we talk about SVMs, we often refer to minimizing a function of the form CA + B. Let's break this down:
- Minimizing A: This part relates to minimizing the misclassification errors. If we set the parameter
Cto be very large, we prioritize minimizing these errors. In other words, ifCis large, we aim to makeAequal to zero. For this to happen: - If
y = 1, we need to find a $\theta$ such that $\theta^Tx \geq 1. - If
y = 0, we need to find a $\theta$ such that $\theta^Tx \leq -1. - Minimizing B: This part relates to maximizing the margin. The margin is the distance between the decision boundary and the nearest data point from either class. The optimization problem can be expressed as:
$$ \begin{aligned} \text{minimize}\ \frac{1}{2} \sum_{j=1}^{m} \theta_j^2 \\ \text{subject to}\ \theta^Tx^{(i)} \geq 1\ \text{if}\ y^{(i)}=1 \\ \theta^Tx^{(i)} \leq -1\ \text{if}\ y^{(i)}=0 \end{aligned} $$
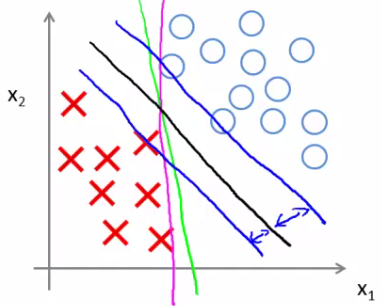
Visualization of Large Margin Classification
In the visualization, the green and magenta lines are potential decision boundaries that might be chosen by a method like logistic regression. However, these lines might not generalize well to new data. The black line, chosen by the SVM, represents a stronger separator. It is chosen because it maximizes the margin, the minimum distance to any of the training samples.
Understanding the Decision Boundary in SVMs
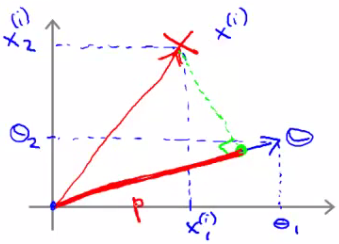
Assuming we have only two features and $\theta_0 = 0$, we can rewrite the minimization of B as:
$$\frac{1}{2}(\theta_1^2 + \theta_2^2) = \frac{1}{2}(\sqrt{\theta_1^2 + \theta_2^2})^2 = \frac{1}{2}||\theta||^2$$
This is essentially minimizing the norm of the vector $\theta$. Now, consider what $\theta^Tx$ represents in this context. If we have a positive training example and we plot $\theta$ on the same axis, we are interested in the inner product of these two vectors, denoted as p.
pis actuallyp^i, representing the projection of the training exampleion the vector $\theta$.- The conditions for the classification become:
$$ \begin{aligned} p^{(i)} \cdot ||\theta|| &\geq 1\ \text{if}\ y^{(i)}=1 \\ p^{(i)} \cdot ||\theta|| &\leq -1\ \text{if}\ y^{(i)}=0 \end{aligned} $$
Adapting SVM to Non-linear Classifiers
Support Vector Machines (SVMs) can be adapted to find non-linear boundaries, which is crucial for handling datasets where the classes are not linearly separable.
Non-linear Classification
Consider a training set where a linear decision boundary is not sufficient. The goal is to find a non-linear boundary that can effectively separate the classes.
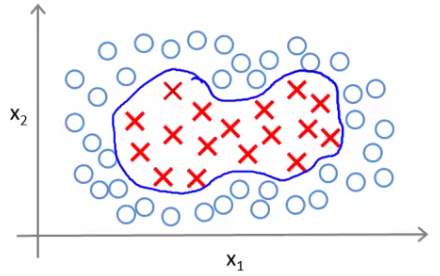
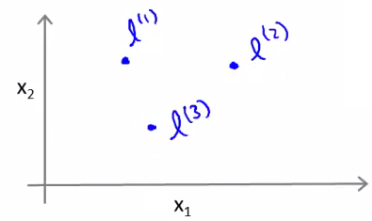
Introducing Landmarks and Features
-
Defining Landmarks: We start by defining landmarks in our feature space. Landmarks ($l^1$, $l^2$, and $l^3$) are specific points in the feature space, chosen either manually or by some heuristic.
-
Kernel Functions: A kernel is a function that computes the similarity between each feature $x$ and the landmarks. For example, the Gaussian kernel for a landmark $l^1$ is defined as:
$$f_1 = k(x, l^1) = \exp\left(- \frac{||x - l^{(1)}||^2}{2\sigma^2}\right)$$
``- A large $\sigma^2$ leads to smoother feature variation (higher bias, lower variance).
- A small $\sigma^2$ results in abrupt feature changes (low bias, high variance).
``
-
Prediction Example: Consider predicting the class of a new point (e.g., the magenta dot in the figure). Using our kernel functions and a specific set of $\theta$ values, we can compute the classification.
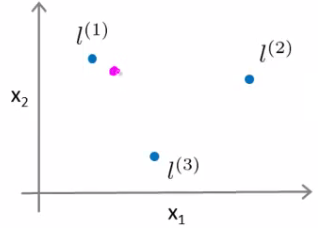
For a point close to $l^1$, $f_1$ will be close to 1, and others will be closer to 0. Hence, for $\theta_0 = -0.5, \theta_1 = 1, \theta_2 = 1, \theta_3 = 0$, the prediction will be 1.
Choosing Landmarks
- Landmarks are often chosen to be the same as the training examples, resulting in
mlandmarks formtraining examples. - Each example's feature set is evaluated based on its proximity to each landmark using the chosen kernel function.
Different Kernels
- Linear Kernel: Equivalent to no kernel, predicts $y = 1$ if $(\theta^T x) \geq 0$.
- Gaussian Kernel: Useful for creating complex non-linear boundaries.
- Other types of kernels include Polynomial, String, Chi-squared, and Histogram Intersection kernels.
Logistic Regression vs. SVM in Non-linear Classification
- High Feature Count (n) Compared to Examples (m): Use logistic regression or SVM with a linear kernel.
- Small n, Intermediate m: Gaussian kernel with SVM is suitable.
- Small n, Large m: SVM with Gaussian kernel may be slow; logistic regression or SVM with a linear kernel is preferred.
- SVM's Power: The ability to use different kernels makes SVMs versatile for learning complex non-linear functions.
- Convex Optimization: SVMs provide a global minimum, ensuring consistency in the solution.
Reference
These notes are based on the free video lectures offered by Stanford University, led by Professor Andrew Ng. These lectures are part of the renowned Machine Learning course available on Coursera. For more information and to access the full course, visit the Coursera course page.