Large Scale Machine Learning
Training machine learning models on large datasets poses significant challenges due to the computational intensity involved. To effectively handle this, various techniques such as stochastic gradient descent and online learning are employed. Let's delve into these methods and understand how they facilitate large-scale learning.
Learning with Large Datasets
To achieve high performance, one effective approach is using a low bias algorithm on a massive dataset. For example:
- Scenario: Consider a dataset with
m = 100,000,000examples. - Challenge: Training a model like logistic regression on this scale requires significant computation for each gradient descent step.
Logistic Regression Update Rule:
$$ \theta_j := \theta_j - \alpha \frac{1}{m} \sum_{i=1}^m(h_{\theta}(x^{(i)}) - y^{(i)}) x_j^{(i)} $$
- Approach: Experiment with a smaller sample (say, 1000 examples) to test performance.
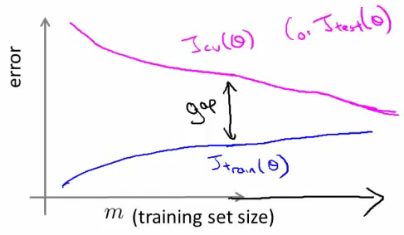
Diagnosing Bias vs. Variance:
- A large gap between training and cross-validation errors indicates high variance, suggesting more data might help.
- A small gap implies high bias, where additional data may not improve performance.
Stochastic Gradient Descent (SGD)
SGD optimizes the learning process for large datasets by updating parameters more frequently:
-
Batch Gradient Descent: Traditional method that sums gradient terms over all examples before updating parameters. It's inefficient for large datasets.
-
SGD Approach: Randomly shuffle the training examples. Update $\theta_j$ for each example:
$$ \theta_j := \theta_j - \alpha (h_{\theta}(x^{(i)}) - y^{(i)}) x_j^{(i)} $$
- This results in parameter updates for every training example, rather than at the end of a full pass over the data.
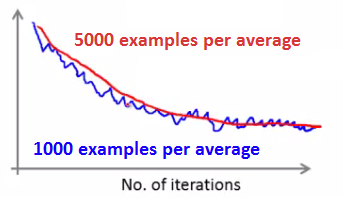
- Convergence Observation: Observe the cost function versus the number of iterations.
Online Learning
- Concept: Online learning is a dynamic form of learning where the model updates its parameters as new data arrives.
- Use Case: Ideal for continuously evolving datasets or when data comes in streams.
- Advantage: Allows the model to adapt to new trends or changes in the data over time.
Example: Product Search on a Cellphone Website
Imagine a cellphone-selling website scenario:
- User Queries: Users enter queries like "Android phone 1080p camera."
- Ranking Phones: The objective is to present the user with a list of ten phones, ranked according to their relevance or appeal.
- Feature Vectors: Generate a feature vector (x) for each phone, tailored to the user’s specific query.
- Click Prediction (CTR): Learn the probability $p(y = 1 | x; \theta)$, where $y = 1$ if a user clicks on a phone link, and $y = 0$ otherwise. This probability represents the predicted click-through rate (CTR).
- Utilizing CTR: Rank and display phones based on their estimated CTR, showing the most likely to be clicked options first.
Online Learning
- Concept: Online learning is a dynamic form of learning where the model updates its parameters as new data arrives.
- Use Case: Ideal for continuously evolving datasets or when data comes in streams.
- Advantage: Allows the model to adapt to new trends or changes in the data over time.
Example: Product Search on a Cellphone Website
Imagine a cellphone-selling website scenario:
- User Queries: Users enter queries like "Android phone 1080p camera."
- Ranking Phones: The objective is to present the user with a list of ten phones, ranked according to their relevance or appeal.
- Feature Vectors: Generate a feature vector (x) for each phone, tailored to the user’s specific query.
- Click Prediction (CTR): Learn the probability $p(y = 1 | x; \theta)$, where $y = 1$ if a user clicks on a phone link, and $y = 0$ otherwise. This probability represents the predicted click-through rate (CTR).
- Utilizing CTR: Rank and display phones based on their estimated CTR, showing the most likely to be clicked options first.
Here's a mock implementation of a Online Learning using Python:
Step 1: Data Collection
Collect data on user queries and clicks on phone links. For simplicity, let's assume the data looks like this:
| User Query | Phone ID | Features (x) | Click (y) |
| "Android phone 1080p camera" | 1 | [0.8, 0.2, 0.9, 0.4] | 1 |
| "Android phone 1080p camera" | 2 | [0.6, 0.4, 0.8, 0.5] | 0 |
| "Cheap iPhone" | 3 | [0.3, 0.9, 0.5, 0.7] | 1 |
| ... | ... | ... | ... |
Step 2: Feature Extraction
Extract feature vectors for each phone based on user queries. These features can include attributes like price, camera quality, battery life, etc.
Step 3: Model Initialization
Initialize a simple logistic regression model for CTR prediction:
from sklearn.linear_model import SGDClassifier
import numpy as np
# Initialize the model
model = SGDClassifier(loss='log', learning_rate='constant', eta0=0.01)
# Assume initial training data (for illustration purposes)
X_initial = np.array([[0.8, 0.2, 0.9, 0.4], [0.6, 0.4, 0.8, 0.5], [0.3, 0.9, 0.5, 0.7]])
y_initial = np.array([1, 0, 1])
# Initial training
model.partial_fit(X_initial, y_initial, classes=np.array([0, 1]))Step 4: Online Learning Process
Update the model with new data as it arrives:
def update_model(new_data):
X_new = np.array([data['features'] for data in new_data])
y_new = np.array([data['click'] for data in new_data])
model.partial_fit(X_new, y_new)
# Example of new data arriving
new_data = [
{'features': [0.7, 0.3, 0.85, 0.45], 'click': 1},
{'features': [0.5, 0.5, 0.75, 0.55], 'click': 0},
]
# Update the model with new data
update_model(new_data)Step 5: Ranking Phones
Predict the CTR for new user queries and rank the phones accordingly:
def rank_phones(user_query, phones):
# Extract features for each phone based on the user query
feature_vectors = [phone['features'] for phone in phones]
# Predict CTR for each phone
predicted_ctr = model.predict_proba(feature_vectors)[:, 1]
# Rank phones by predicted CTR
ranked_phones = sorted(zip(phones, predicted_ctr), key=lambda x: x[1], reverse=True)
return ranked_phones[:10]
# Example phones data
phones = [
{'id': 1, 'features': [0.8, 0.2, 0.9, 0.4]},
{'id': 2, 'features': [0.6, 0.4, 0.8, 0.5]},
{'id': 3, 'features': [0.3, 0.9, 0.5, 0.7]},
# More phones...
]
# Rank phones for a given user query
top_phones = rank_phones("Android phone 1080p camera", phones)
print(top_phones)Map Reduce in Large Scale Machine Learning
Map Reduce is a programming model designed for processing large datasets across distributed clusters. It simplifies parallel computation on massive scales, making it a cornerstone for big data analytics and machine learning where traditional single-node processing falls short.
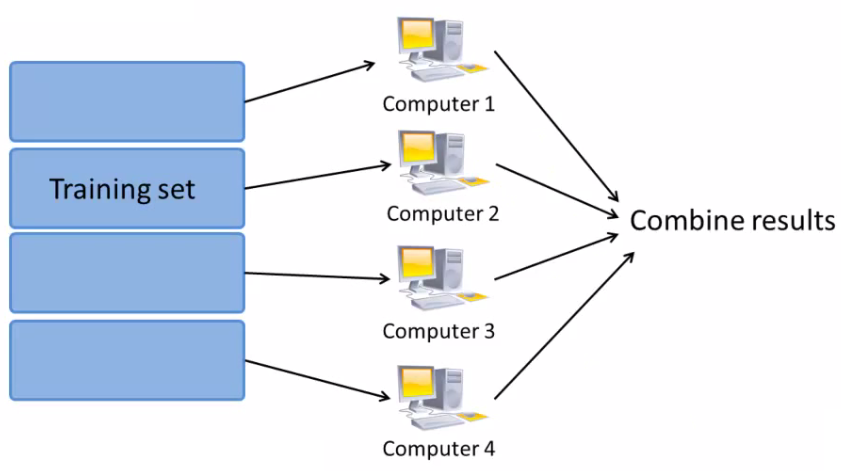
Understanding Map Reduce
Map Reduce works by breaking down the processing into two main phases: Map phase and Reduce phase.
I. Map Phase:
- Operation: This phase involves taking a large input and dividing it into smaller sub-problems. Each sub-problem is processed independently.
- Function: The map function applies a specific operation to each sub-problem. For example, it might involve filtering data or sorting it.
- Output: The result of the map function is a set of key-value pairs.
II. Reduce Phase:
- Operation: In this phase, the output from the map phase is combined or reduced into a smaller set of tuples.
- Function: The reduce function aggregates the results to form a consolidated output.
- Examples: Summation, counting, or averaging over large datasets.
Implementation of Map Reduce
One popular framework for implementing Map Reduce is Apache Hadoop, which handles large scale data processing across distributed clusters.
Hadoop Ecosystem:
- Hadoop Distributed File System (HDFS): Splits data into blocks and distributes them across the cluster.
- MapReduce Engine: Manages the processing by distributing tasks to nodes in the cluster, handling task failures, and managing communications.
Process Flow:
- Data Distribution: Data is split and distributed across the HDFS.
- Job Submission: A MapReduce job is defined and submitted to the cluster.
- Mapping: The map tasks process the data in parallel.
- Shuffling: Data is shuffled and sorted between the map and reduce phases.
- Reducing: Reduce tasks aggregate the results.
- Output Collection: The final output is assembled and stored back in HDFS.
Here's a mock implementation of a MapReduce job using Python and Hadoop Streaming:
Step 1: Data Distribution
Assume we have a text file input.txt containing the following data:
Hello world
Hello Hadoop
Hadoop is greatThis data is stored in HDFS, which will handle data distribution.
Step 2: Job Submission
We will create two Python scripts: one for the mapper and one for the reducer. These scripts will be used in the Hadoop Streaming job submission.
Step 3: Mapper Script
mapper.py:
#!/usr/bin/env python
import sys
# Read input line by line
for line in sys.stdin:
# Remove leading and trailing whitespace
line = line.strip()
# Split the line into words
words = line.split()
# Output each word with a count of 1
for word in words:
print(f'{word}\t1')Make sure the script is executable:
chmod +x mapper.pyStep 4: Shuffling
The Hadoop framework handles the shuffling and sorting of data between the map and reduce phases. No additional code is needed for this step.
Step 5: Reducer Script
reducer.py:
#!/usr/bin/env python
import sys
current_word = None
current_count = 0
word = None
# Read input line by line
for line in sys.stdin:
# Remove leading and trailing whitespace
line = line.strip()
# Parse the input we got from mapper.py
word, count = line.split('\t', 1)
# Convert count (currently a string) to int
try:
count = int(count)
except ValueError:
# Count was not a number, so silently ignore/discard this line
continue
# This IF-switch only works because Hadoop sorts map output
# by key (here: word) before it is passed to the reducer
if current_word == word:
current_count += count
else:
if current_word:
# Write result to stdout
print(f'{current_word}\t{current_count}')
current_word = word
current_count = count
# Do not forget to output the last word if needed
if current_word == word:
print(f'{current_word}\t{current_count}')Make sure the script is executable:
chmod +x reducer.pyStep 6: Job Submission and Execution
Submit the MapReduce job to the Hadoop cluster using the Hadoop Streaming utility:
hadoop jar /path/to/hadoop-streaming.jar \
-input /path/to/input/files \
-output /path/to/output/dir \
-mapper /path/to/mapper.py \
-reducer /path/to/reducer.py \
-file /path/to/mapper.py \
-file /path/to/reducer.pyExample Job Submission
Assuming the input file is stored in HDFS at /user/hadoop/input/input.txt and the output directory is /user/hadoop/output/, the job submission would look like this:
hadoop jar /usr/lib/hadoop-mapreduce/hadoop-streaming.jar \
-input /user/hadoop/input/input.txt \
-output /user/hadoop/output/ \
-mapper mapper.py \
-reducer reducer.py \
-file mapper.py \
-file reducer.pyAdvantages of Map Reduce
- Scalability: Can handle petabytes of data by distributing tasks across numerous machines.
- Fault Tolerance: Automatically handles failures. If a node fails, tasks are rerouted to other nodes.
- Flexibility: Capable of processing structured, semi-structured, and unstructured data.
Applications in Machine Learning
- Large-scale Data Processing: For training models on datasets that are too large for a single machine, especially for tasks like clustering, classification, and pattern recognition.
- Parallel Training: Training multiple models or model parameters in parallel, reducing the overall training time.
- Data Preprocessing: Large-scale data cleaning, transformation, and feature extraction.
Forms of Parallelization
- Multiple Machines: Distribute the data and computations across several machines.
- Multiple CPUs: Utilize several CPUs within a machine.
- Multiple Cores: Take advantage of multi-core processors for parallel processing.
Local and Distributed Parallelization
- Numerical Linear Algebra Libraries: Some libraries can automatically parallelize computations across multiple cores.
- Vectorization: With an efficient vectorization implementation, local libraries might handle much of the optimization, reducing the need for manual parallelization.
- Distributed Systems: For data that's too large for a single system, distributed computing frameworks like Hadoop are used. These frameworks apply the Map Reduce paradigm to process data across multiple machines.
Reference
These notes are based on the free video lectures offered by Stanford University, led by Professor Andrew Ng. These lectures are part of the renowned Machine Learning course available on Coursera. For more information and to access the full course, visit the Coursera course page.